Aligning Latent and Image Spaces to Connect the Unconnectable
ICCV 2021
Abstract
We develop a method to generate infinite high-resolution images with diverse and complex content. It is based on a perfectly equivariant generator with synchronous interpolations in the image and latent spaces. Latent codes, when sampled, are positioned on the coordinate grid, and each pixel is computed from an interpolation of the nearby style codes. We modify the AdaIN mechanism to work in such a setup and train the generator in an adversarial setting to produce images positioned between any two latent vectors. At test time, this allows for generating complex and diverse infinite images and connecting any two unrelated scenes into a single arbitrarily large panorama. Apart from that, we introduce LHQ: a new dataset of 90k high-resolution nature landscapes. We test the approach on LHQ, LSUN Tower and LSUN Bridge and outperform the baselines by at least 4 times in terms of quality and diversity of the produced infinite images.
Live demo [infinite generation + resampling]









This is generation (without truncation tricks/clustered sampling) from a model trained on LHQ \(1024^2\) with FID = 7.8 (images are being resized to \(256^2\) for performance reasons).
The alignment of latent and image spaces
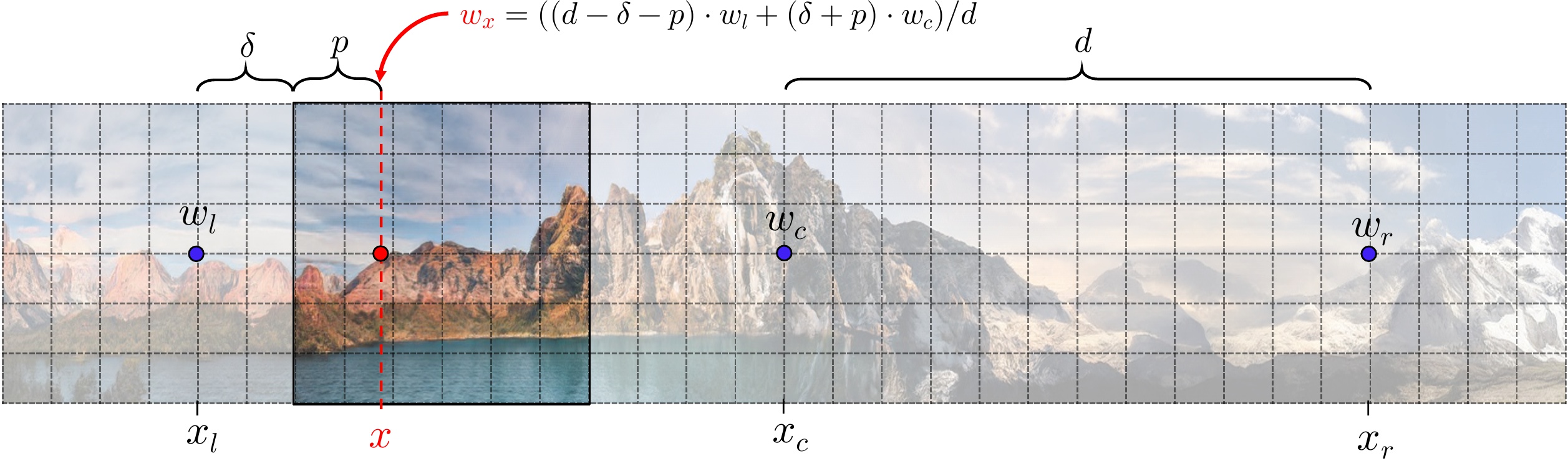
We position (global) latent codes \(w\) on the coordinates grid — the same grid where pixels are located. Each pixel value is computed from the interpolation of nearby latent codes via our Spatially-Aligned AdaIN (SA-AdaIN) mechanism, illustrated below.
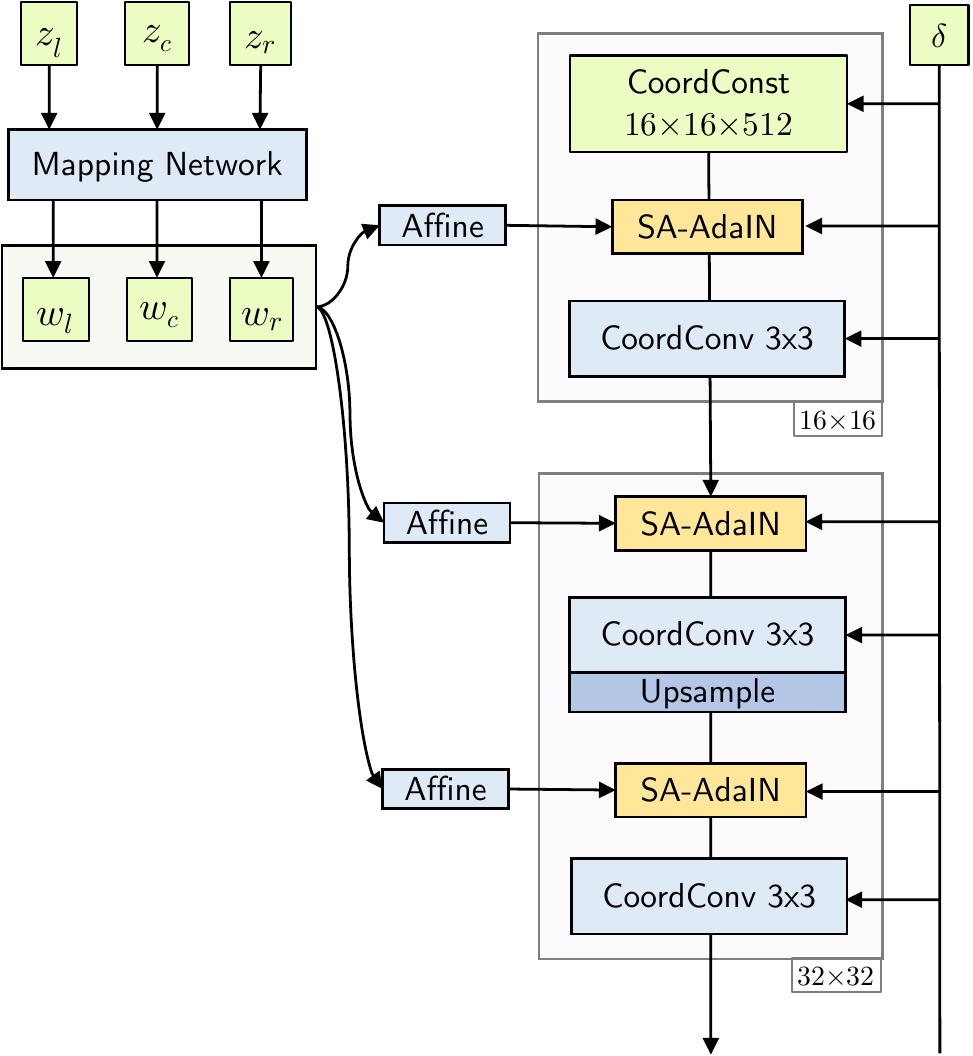
Our generator is based on the StyleGAN2's one, but augmented with coordinates and the weight modulation-demodulation mechanism is replaced with Spatially-Aligned AdaIN — an AdaIN modification which uses interpolated latent codes to produce an output (illustrated below). At each iteration, we sample not only a latent code \(w_c\), which described the middle frame, but also its left/right neigbhours \(w_l\) and \(w_r\) which are positioned at distance \(d\) from \(w_c\). After that, we randomly select a frame (determined by random shift \(\delta\)) on this plane and render it. During the training we use only local relative coordinates — this allows to use any \(\delta \in (-\infty,+\infty)\) interval at test time without any loss in image quality.
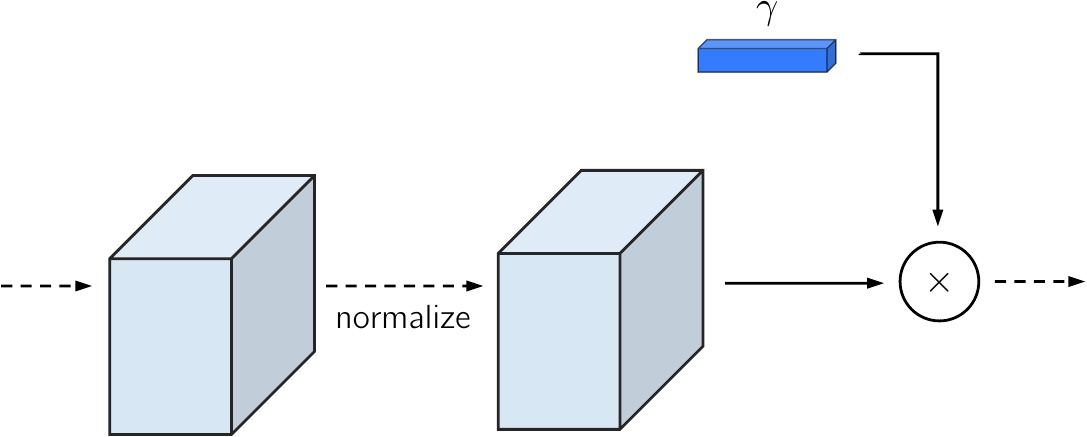
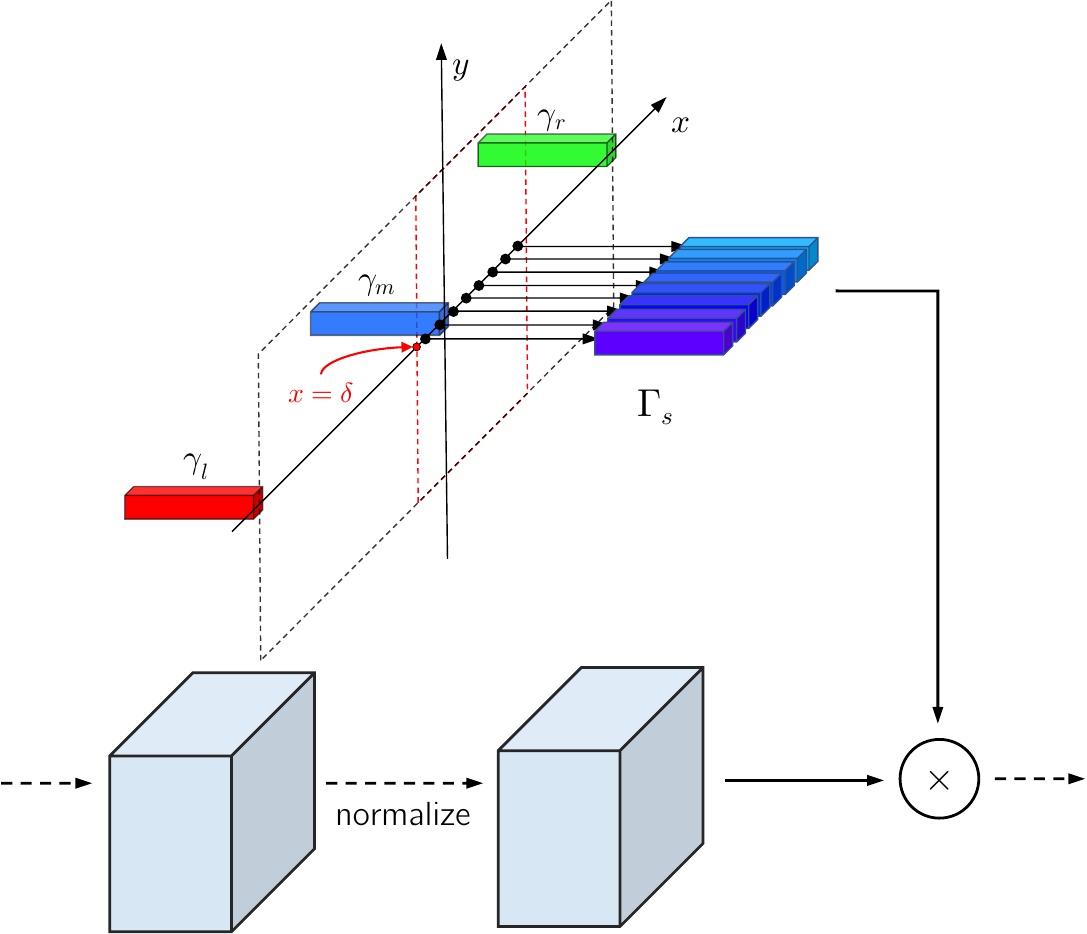
Left — traditional AdaIN (but without shifting). Right — SA-AdaIN.
Shift equivariance of the generator
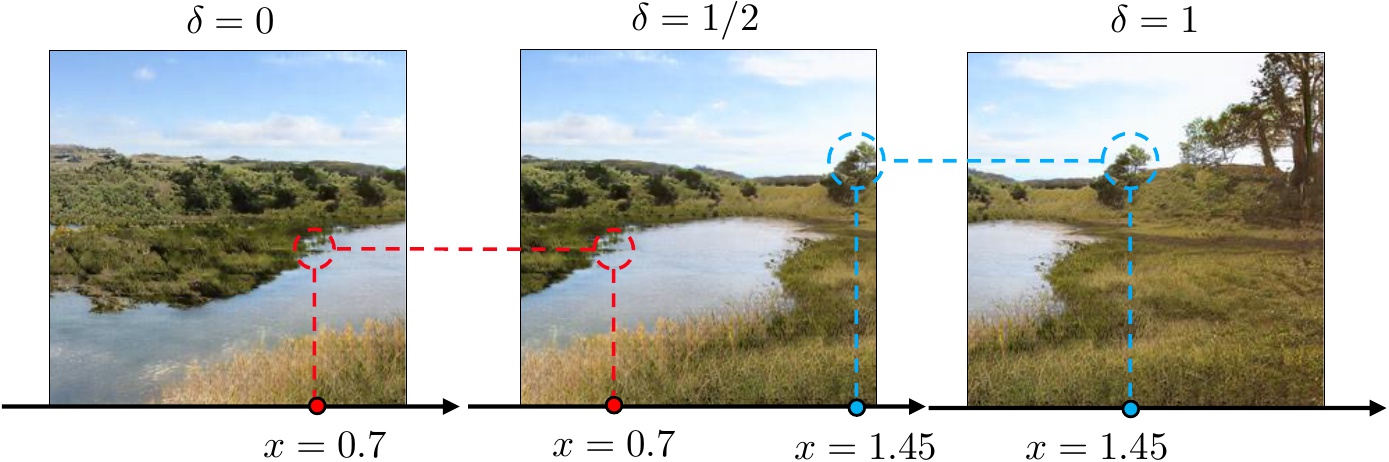
Our generator is (periodically) shift equivariant by construction, which means that when you shift the input coordinates, the output image moves accordingly. It is achieved by building upon the recently proposed INR-GAN model that generates pixels independently and does not require upsampling procedures during the forward pass. But instead of generating all pixels independently, we generate them patch-by-patch, like CocoGAN does.
Connecting the unconnectable

A surprising result is that ALIS generator learns to connect scenes even for LSUN Bedroom — a dataset which does not have spatially invariant statistics, i.e. most of the images have walls on the left/right sides or close-by objects (visualized below) and which makes it very difficult to extrapolate in any direction.

Illustrating the problems with LSUN Bedroom. It has walls and close-by objects that make it prevents its extrapolation in the left/right directions, since the dataset does not contain images that have close-by objects or walls in the middle of the frame.
Landscapes HQ dataset
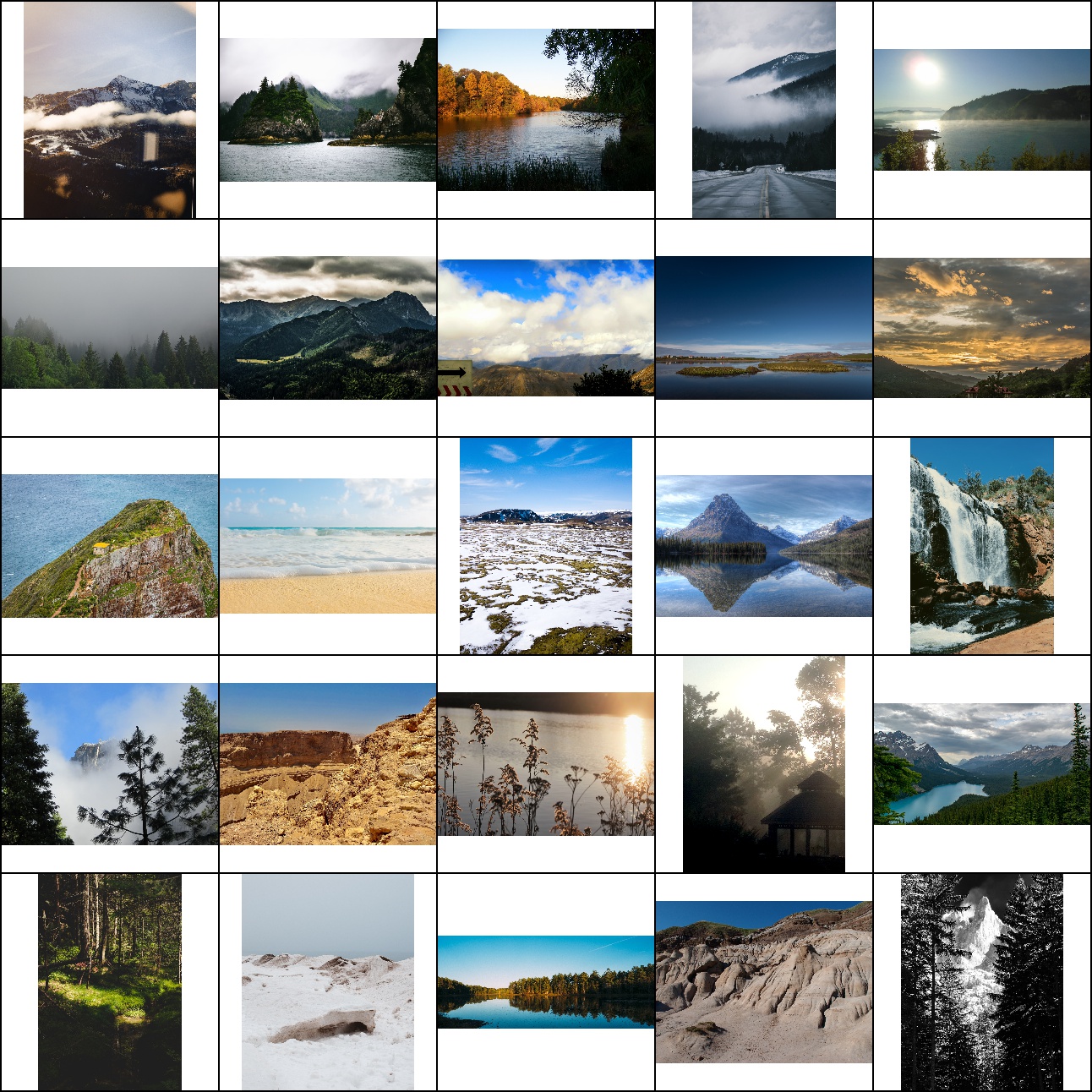
25 random images from LHQ (downsized). The dataset is available for download from the github repo.
BibTeX
@inproceedings{alis,
title={Aligning latent and image spaces to connect the unconnectable},
author={Skorokhodov, Ivan and Sotnikov, Grigorii and Elhoseiny, Mohamed},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={14144--14153},
year={2021}
}